1-5 Let's learn about the principle of image generation by diffusion model(Stable Diffusion Practical Guide Table of Contents)
List
In this chapter, we will explain how Stable Diffusion generates images based on the knowledge learned so far.
Stable Diffusion generates an image from a given text (command). The process involves interpreting the text, removing noise from the latent space that contains the characteristics of the image it represents, and then creating an image after high-resolution processing.
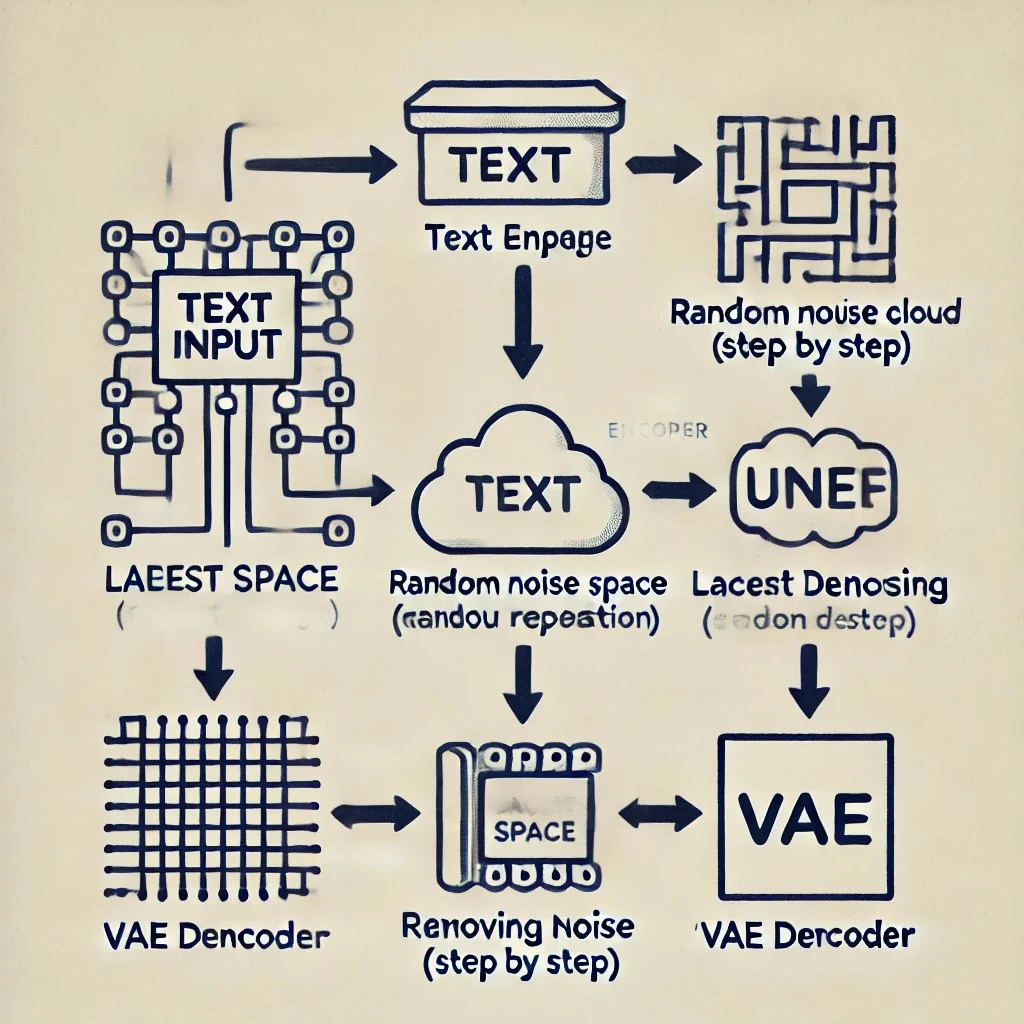
At first, text (prompt and negative prompt) is input into a structure called CLIP. In front of CLIP, there is a large group of artificial neural networks called UNet. Here, 'conditional inverse diffusion' is performed based on the conditions of the given prompt and image association in CLIP. In this inverse diffusion process, the diffusion noise is removed from the 'image of nothing (converted to latent space)' until the final result that meets the given conditions is produced. Through this, the 'image (converted to latent space)' that meets the given conditions is restored. Finally, it is converted from latent space to image through VAE, and the generated image that we can see with our eyes is completed.
These processes are largely performed in a structure formed by three artificial neural networks, and can be understood by dividing them into CLIP, UNet, and VAE, respectively.
>>> CLIP's structure for interpreting language
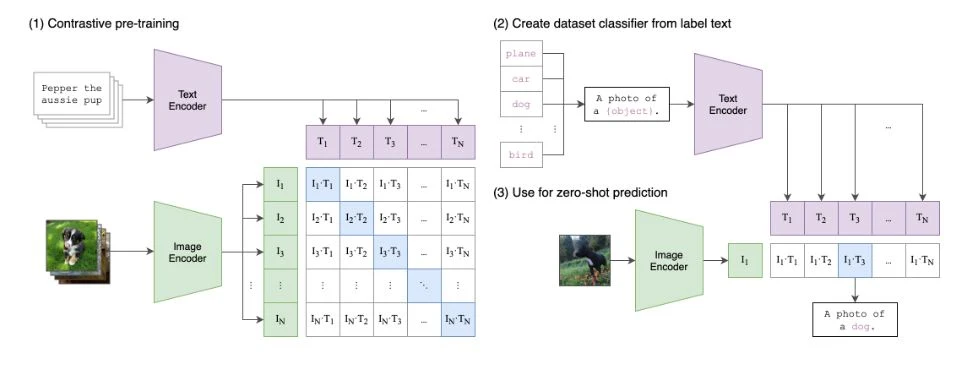
SDXL, which is mainly introduced in this article, applies CLIP-ViT/L developed by OpenAI, open source OpenCLIP-ViT/G, and LAION, a dataset.
GitHub - mlfoundations/open_clip
https://github.com/mlfoundations/open_clip
CLIP (Contrastive Language-Image Pretraining: Autoencoder pretrained on contrastive images and languages) is a multimodal model of language and images released by OpenAI in February 2021 for use in language models and translation. In Stable Diffusion, the text encoder part is used to interpret the prompt.
The basic image generation process starts from the text (prompt) input by the user. First, it interprets the input text to determine what kind of image to create. Then, in order to make it easier to handle in the future process, it converts the interpreted information into a feature data 'latent space', which is a low-dimensional data commonly handled by artificial neural networks. CLIP repeatedly passes this 'latent space' to the next stage to control the direction of image generation.
Why can CLIP interpret language? It is because it has been trained to understand the meaning and relationship between text and images in the process of changing images and language through the latent space, which is a common low-dimensional data. An artificial neural network called a text encoder interprets the prompt and performs an encoding process that breaks down the text into tokens (chunks of text). The tokens broken down here are word units, but they can also be at the character level and can be in various states.
>>> UNet's structure that carries out the creation process
The next structure, UNet, is a huge artificial neural network. It predicts and removes unnecessary noise using very small features and time axis in the noise data as clues, and creates a latent space for specific data.
The 'diffusion model' used in UNet learns a process that adds noise to the latent space of feature data and spreads it along the time axis, and then reversely predicts and removes the added noise from the data in the diffusion state and time information, and then restores the feature data.

When you add noise to an image in Photoshop, the original image is blurry at first, but as the noise gradually spreads, the original image becomes completely indistinguishable, as shown in the upper right. The time progression of this diffusion process is thought to be 'somewhat predictable' from a human perspective. UNet learns this 'backpropagation' process using machine learning.
Utilizing the phenomenon that Gaussian noise spreads in an ideal form continuously over time, it applies 'learning to remove Gaussian noise' in a state where only noise exists, and proceeds with 'conditioning' of CLIP in the process of removing noise.
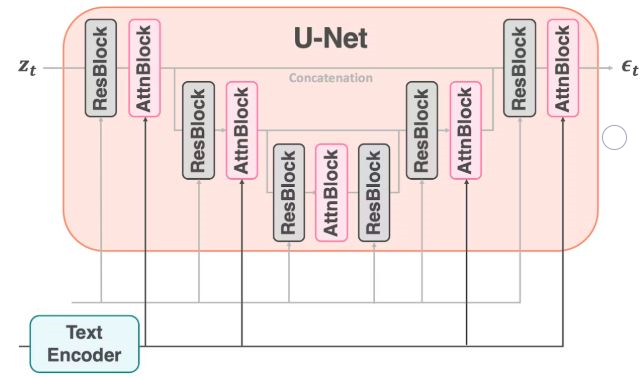
Let's take a closer look at this learning. Since learning is done by comparing before and after diffusion, from the perspective of a single-learning perspective, it conditions the text instructions interpreted by CLIP in the process of predicting and removing noise in the diffusion state. UNet is a network that originally determines the area in medical images such as CT. The UNet of Stable Diffusion consists of a ResBlock called Residual and a block that handles time in the diffusion model, and a block called AttnBlock that uses conditions from CLIP as attention. CLIP uses AttnBlock to paste the conditions into the prompt. Using this, data with text-indicated features can be generated from data in a random diffusion state without features.
>>> Structure of VAE that converts to images
Finally, the VAE decoder is used in the process of converting the 'latent space' of the feature data simulated by UNet into image data so that humans can recognize and handle it.
VAE, including the VAE decoder, can be classified as an autoencoder, just like CLIP. Among them, VAE is specialized in extracting and analyzing feature data from images and being trained to return them to the original images. Among these, the VAE decoder alone can be used to convert the feature data latent space into an image.
Usually, when an image is input, the encoder interprets it once as a 'latent space' and then uses the decoder to return it to an image. The latter half of the process, which can be called information compression, is the role of the decoder.
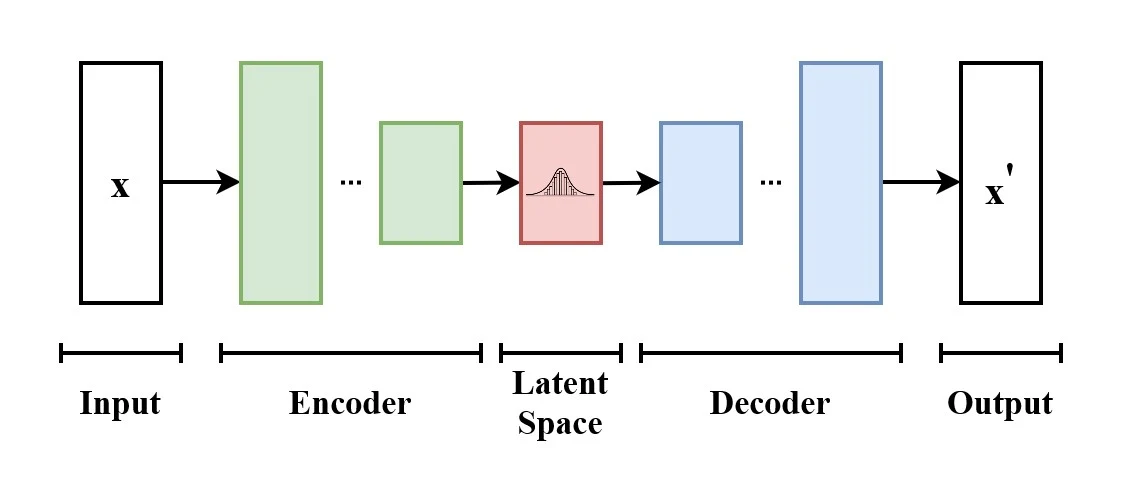
Image source: A thorough explanation of the image-generating AI 'Stable Diffusion' that shocked the world (https://en.wikipedia.org/wiki/Variational_autoencoder)
Combining the three structures that performed pre-learning in the above-mentioned tasks, a structure is created that interprets the input text through the compressed 'latent space' and generates image data with its features pasted in. However, as of now, there is no uniformity in the feature data connecting each structure, so it cannot yet generate the image intended by the user.
In this structure, the input data is 'multiple texts (prompts) that display images' and the output data is 'images' that have the features indicated by the input text (prompts), and the basic design of text image generation is to repeatedly train with a large amount of data, and then achieve the task of interpreting human language and generating images from it. Now, you probably understand it to some extent.
>>>Future development direction of Stable Diffusion
In fact, Stable Diffusion, which was released for free in August 2022, has created a great sensation around the world. On my blog, I focus on Stable Diffusion .5 (SD 1.5), its successor Stable Diffusion 2.1 (SD 2.1), and the latest model, Stable Diffusion XL (SDXL), which has strengths in spatial expression of light and shadow. In addition to VAE, SDXL adds an image quality improvement function called Refiner, and two text encoders (OpenCLIP-ViT/G and CLIP-ViT/L) are applied to the base model, enabling more diverse pasting into the 'latent space'. This means that two prompts can be run at the same time. In this way, Stable Diffusion is evolving day by day.
Recently, it was announced that Stable Diffusion Cascade, which can generate images at high speed, Stable Video Diffusion, which can generate videos, and Stable Diffusion 3, which can generate high-quality text, will all be launched as open source. The research leading up to this point can be said to have been rapidly popularized and developed because the image synthesis research called SDEdit was shared for free to the public.
Researchers and developers around the world, including those who developed models that can synthesize videos like OpenAI's Sora, are currently studying and comparing them and making progress. If we were to simply marvel at new technologies, we would quickly fall behind. Let's try the technologies ourselves and test them out.
Although it was long, in Chapter 1, we experienced text image generation, learned about the profound and grand history of the technologies behind it, and explained the internal structure of Stable Diffusion in an easy-to-understand manner. With this, you should have a little understanding of the historical flow of Stable Diffusion and how it generates images. In the following Chapter 2, we will actually build the three structures introduced here in a cloud environment and on a computer. From now on, let's learn the basics and structure of artificial intelligence technology and image generation techniques.



Comments
Post a Comment